次世代型データインフラを構築・提供するスタートアップのVisual Bankは、提供するAI学習用データソリューション「Qlean Dataset(キュリンデータセット)」にて、研究・商業AI開発に対応した7万時間超の日本語音声データセットを販売開始しました。

教育・医療・ビジネス領域に活用可能
Qlean Datasetが提供するした日本語音声データセットは、同サービスのオリジナルデータラインナップ「データレシピ」に追加されたものです。
「データレシピ」は用途や精度・納期に応じて、すぐに使えるデータ素材を柔軟に組み合わせられる構成を特徴としており、一部アノテーション済み/未付与のデータや、個別要件に応じた構成変更・拡張にも対応しています。
今回新たに追加された日本語音声データセットは合計7万時間超であり、朗読や授業、テキスト読み上げなどから成る「1話者音声」、ビジネス会話や電話の会話などから成る「2話者音声」、さらにグループ会話やテレビ番組の会話を模した「3話者以上の音声」と、多様な収録形式が用意されています。
Qlean Datasetは、今後も千葉ロッテマリーンズや東洋経済新報社をはじめとする国内外のネットワークを拡充する模様です。
Qlean Datasetとは
「Qlean Dataset」は、Visual Bankが提供するAI開発に必要な高品質な学習用データを提供するサービスです。著作権や肖像権といった権利処理が厳格に行われた画像、動画、音声、テキストなどを提供。人物の顔や動作、街並み、乗り物など、多様なデータセットを扱っています。オーダーメイドでのデータ制作も可能です。また、大学や研究機関向けに、一部データを無償提供する「アカデミア支援プログラム」も実施しています。
参照元:Qlean Dataset、7万時間超の多様なシーンの日本語音声データセットを販売開始
RELATED|関連記事
-
音声チャットアプリ「buz」、クロちゃんの音声フィルターをリリース
 2025/10/17
2025/10/17

-
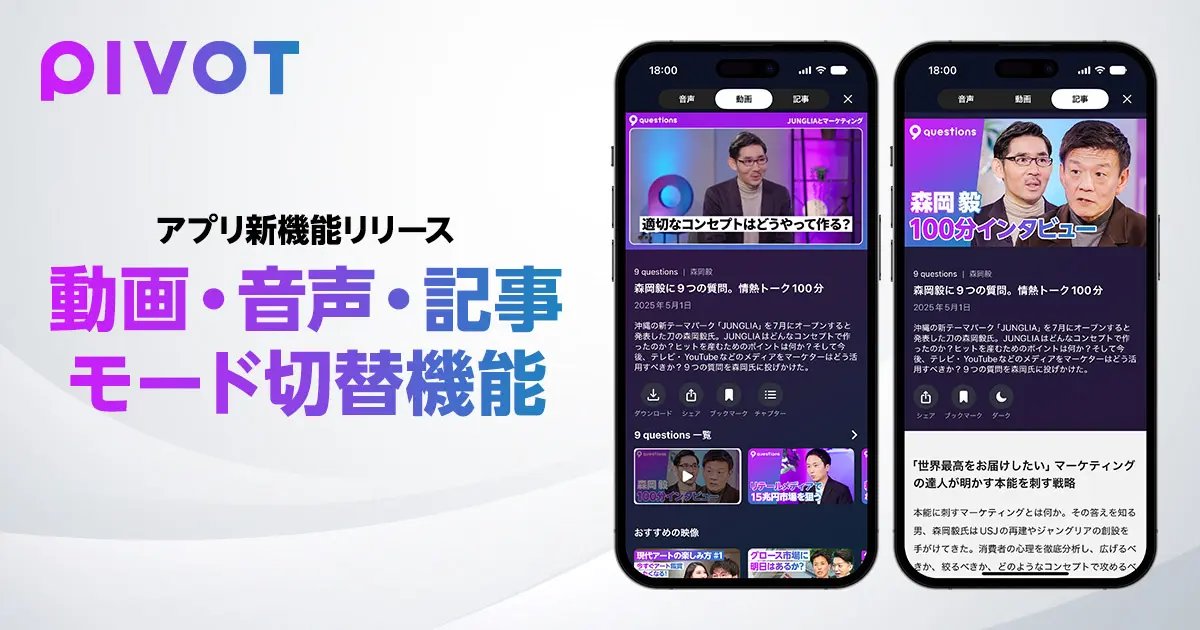
ビジネス映像メディア「PIVOT」、アプリで音声版と記事版を提供開始
2025/05/31
-
電通、AIコピーライターを活用しキリンビール「淡麗プラチナダブル」の音声広告を制作


7万時間、人間にとってはとてつもない長さだ…。