NVIDIAは、音声入力からリアルな顔の動きや表情を自動生成するAIモデル「Audio2Face」を9月にオープンソースで公開しました。開発者や企業が自社環境で自由に活用できるようになり、音声と映像を融合した新たな表現の可能性が広がっています。
AI「Audio2Face」をオープンソース化
NVIDIAは、音声入力から3Dキャラクターの顔の動きや表情を自動生成するAIモデル「Audio2Face」をオープンソースで公開しました。開発者や企業が自社環境でAudio2Faceを活用できるようになり、3Dキャラクター制作の柔軟性が高まりました。
Audio2Faceは、音声データから発音やイントネーションを解析し、自然な表情アニメーションを生成するAIモデルです。既存の手作業アニメーションに比べて制作を効率化し、リアルタイム生成にも対応します。
今回の公開には、AIモデル本体のほか、SDK、プラグイン、トレーニング用フレームワークが含まれています。NVIDIAは「Audio2Face Regression v2.2」と「Diffusion v3.0」の2種類のモデルを提供し、開発者は自社データを用いた再学習やカスタマイズを行うことが可能です。また、Unreal EngineやAutodesk Maya向けのプラグインも用意されており、既存の制作環境に統合しやすい構成になっています。
音声と感情を連動させたフェイシャルAIの仕組み
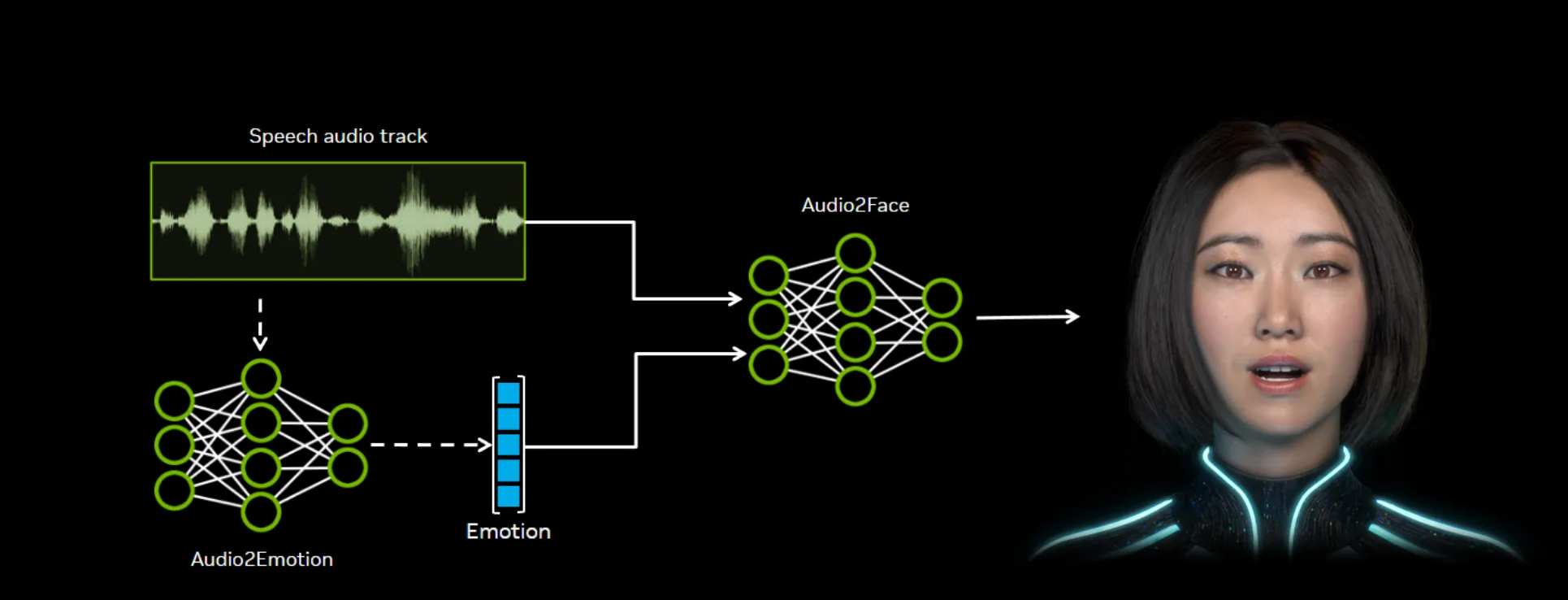
NVIDIAによると、Audio2Faceは音声信号から感情を推定する「Audio2Emotion」モデルと連携して動作する設計になっています。これにより、口の動きだけでなく、感情に基づいた表情表現にも対応できる構造です。公開された図では、音声データがネットワークを通じてEmotion(感情ベクトル)とFace(顔の動き)に分岐し、それらを統合して最終的な3Dアニメーションを生成する仕組みが説明されています。
Audio2Faceは、NVIDIAのリアルタイム3D制作プラットフォーム「Omniverse」に統合されており、ゲームやデジタルヒューマン、映像制作などの分野で活用されています。今回のオープンソース化によって、研究者や企業がより柔軟に技術を利用できるようになり、高品質なフェイシャルアニメーションの利用機会が広がるとしています。NVIDIAはAudio2Faceを通じて、AIを活用した3Dキャラクター表現の普及を後押しする姿勢を示しました。
NVIDIAとは
NVIDIAは、米国カリフォルニア州に本社を置くテクノロジー企業です。GPU(グラフィックス処理装置)の開発で世界的に知られ、ゲーム、映像制作、データセンター、AI、ロボティクスなど幅広い分野で製品とプラットフォームを提供しています。近年は生成AIや自動運転、HPC(高性能計算)向けの半導体開発にも注力し、AI時代を支えるコアテクノロジー企業として業界をリードしています。
参照元:NVIDIA Open Sources Audio2Face Animation Model
RELATED|関連記事
-
ビデオポッドキャストの人気は2年で4倍に。Sweet Fish Mediaが調査。
 2025/07/03
2025/07/03

-
テレビ朝日の新ドラマ『しあわせな結婚』、ポッドキャストと連動した新企画始動
 2025/04/17
2025/04/17

-


声が表情になるなんて、“話す”ってこと自体が進化してる。