中国を拠点とするテクノロジー企業アリババは、1月22日に音声生成モデル「Qwen3-TTS」をオープンソースとしてGitHubやHugging Faceなどで公開しました。話者の声を再現するボイスクローンや、自然言語の指示で声を設計するボイスデザイン、多言語対応機能を備え、ローカル環境での実行にも対応しています。
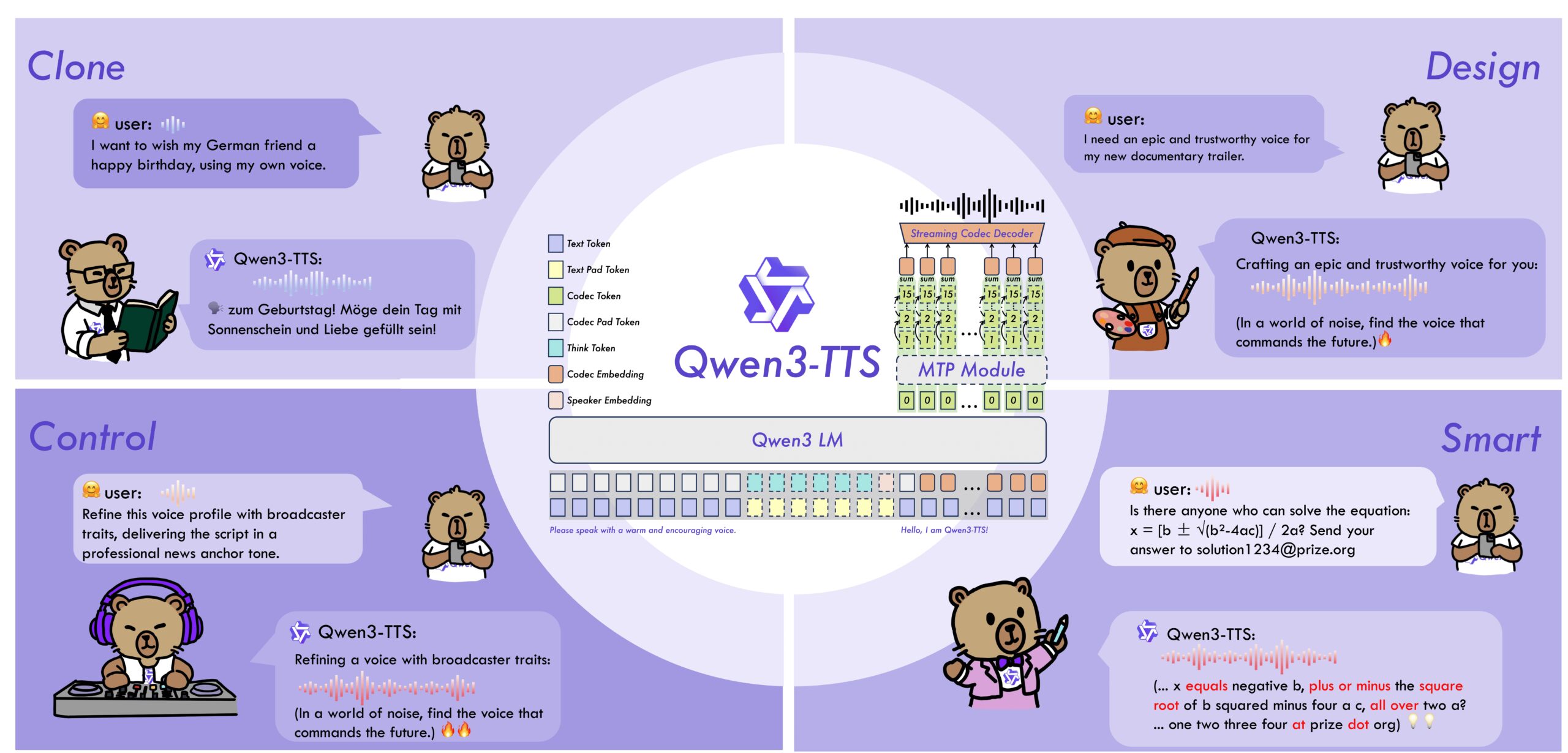
音声合成を担う「Qwen3-TTS」をQwenシリーズとして公開
Qwen3-TTSは、アリババのQwenチームが開発した音声生成モデル群です。テキストから音声を生成するTTS機能を中心に、End-to-Endアーキテクチャを採用することで、最短97msという極めて低いレイテンシでのストリーミング生成を実現しています。
GitHubで公開されたリポジトリでは、ソースコードとともにモデルの概要や利用方法が詳細に解説されています。外部サービスを介さず、モデルウェイトをダウンロードしてローカル環境で直接動作させることが可能です。
ボイスクローンや多言語対応、柔軟な音声制御も
Qwen3-TTSは一般的なテキスト音声合成に加え、わずか3秒の音声サンプルから話者の声を再現するボイスクローン機能に対応しています。
また、日本語、英語、中国語を含む10カ国語をサポートしており、多言語での音声生成が可能です。さらに、声のトーンや話し方を自然言語で指定できる「ボイスデザイン」機能も備えています。「怒ったような声で」「明るい女性の声で」といったテキストによる指示(プロンプト)に基づき、感情やスタイルを柔軟に制御した音声を生成できる点が大きな特徴です。
Qwenとは
Qwenは、AlibabaのQwenチームが開発・公開している大規模言語モデル(LLM)シリーズです。テキスト生成や要約、翻訳、コード生成などの用途に対応し、オープンソースモデルとしてGitHubやHugging Faceなどで公開されています。複数のモデルサイズが用意されており、研究や開発用途で利用されています。
RELATED|関連記事
-

-
ソニー、プレイステーションの歴史をたどる特設ページを公開。起動音とともに記憶を振り返る
2024/12/04

-


音声合成も、ついに「試せる技術」として手元に降りてきた感じがする。